The Hardest Easy DP problem
You are given an array consisting of $n$ positive integers. You are standing at the first index, and you want to reach the last index. You can make as many forward jumps as you want. If you jump from index $i$ to $j$ your profit is $(j - i) \cdot a[i]$. What is the maximum total sum of profits that you can achieve?
The constraints are $n \leq 10^3$.
This looks like a classical textbook DP problem (and it is). Let’s define $dp[i]$ to be the maximum profit when you start your journey at index $i$. The answer to the original problem is then $dp[0]$.
For the transitions, you can try making a jump to all the indices to the right, and recursively pick the optimal jump that gives you the maximum profit.
$$ dp[i] = \text{max} \\{(j - i) \cdot a[i] + dp[j] \\} \qquad j > i $$// dp[i] is the maximum score when you start at index i.
vector<long long> dp(n, 0);
for (int i = n - 1; i >= 0; i--) {
for (int j = i + 1; j < n; j++) {
dp[i] = max(dp[i], 1LL * (j - i) * a[i] + dp[j]);
}
}
return dp[0];
The time complexity of this DP is $\mathcal{O}(n^2)$. But can we optimize it to something better, like $\mathcal{O}(n \cdot log (n))$?
And here’s the interesting part : this optimization is harder than you think or easier than you think, depending upon your skill level. I’ve asked several people this problem, and it’s usually the smarter ones (in terms of competitive programming) who have a hard time coming up with the optimization.
If you’ve watched my video on Optimizing DP with Sliding Window, you might think of separating the $i$ and $j$ terms, and then using sets/heaps/priority-queues to quickly compute terms dependent on $j$.
$$ dp[i] = \text{max} \\{j \cdot a[i] - i \cdot a[i] + dp[j] \\} \qquad j > i $$Notice that $i \cdot a[i]$ is constant for a fixed $i$. So we only need a data structure for fast computation of $j \cdot a[i] + dp[j]$. Problem is, not even a lazy segment tree can do this computation. So how do we optimize it then?
But if I show you the optimization, you’ll be unable to unsee it. Hindsight is 20/20, so I want you to think hard about the optimization before reading the next part.
In the remaining part of the blog, I’ll show you how to arrive at it intuitively.
Let’s start with the bruteforce approach. What is the maximum number of jumps that we can make? It’s $n - 1$. So let’s consider this path, that makes all the jumps linearly.

Note that the optimal path is a subset of this (it’d only contain some of these $n - 1$ jumps). We will try to incrementally remove all the jumps that are unnecessary.
Let’s think recursively, assume that we have already removed some of these unnecessary jumps, and we are currently in this state. How do we figure out which jump to remove next?

What does $(j - i) \cdot a[i]$ represent? It signifies the distance between the two points multiplied by the initial point’s value.
The current profit is $a \cdot d_1 + b \cdot d_2$. If we want to compress these 2 jumps into a single jump, thus eliminating the middleman $b$, the profit that we would get is $a \cdot (d_1 + d_2)$.
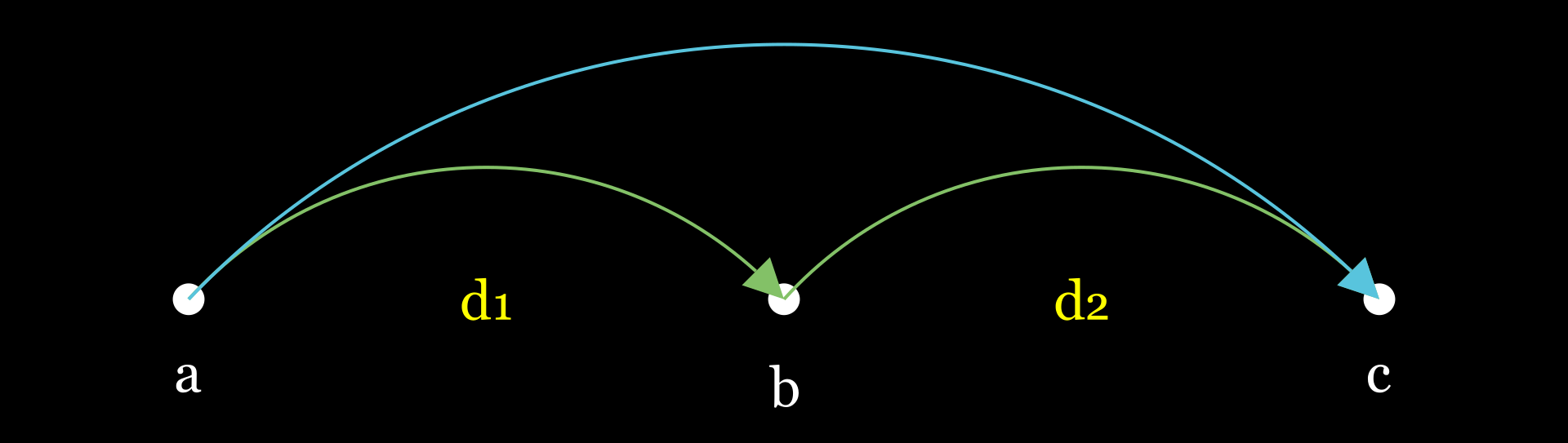
Therefore, if $b > a$, it makes sense to use it as a stepping stone in our jump. Otherwise, we should get rid of the middleman. This means that an optimal jump will always be to an element which is strictly greater than the current value. In fact, it tells us more : the optimal jump has to be to the next element which is strictly greater than the current value. Why? Because if you miss this checkpoint, you could’ve amassed more profit by stopping at it instead.
So, the DP transitions can now be done in $O(1)$ without the need of any data structures. You’ve solved the problem in $O(n)$.
Here’s a different visualization to arrive at the same answer. Assume that you are driving a sports car and there are $n$ gas stations containing one luxury car each. Each time you arrive at the gas station, you can either exchange your car (for free) or do nothing. Each time you stop at a gas station, you get a profit equal to the cost of the car that you currently drove multiplied by the distance you covered.
In this setting, you can clearly see that as soon as you pass by a gas station which has a better car than you’re currently driving, you should stop and upgrade the car immediately. Afterall, why do you want to cover the remaining journey with a low end car when you are getting a better one for free?
long long price = a[0], ans = 0;
int last_cp = 0;
for (int i = 1; i < n; i++) {
// If you are given the option of upgrading the car, you should
// always take it.
// The last index is always a checkpoint.
if (a[i] >= price || i == n - 1) {
ans += price * (i - last_cp);
price = a[i];
last_cp = i;
}
}
return ans;
And that’s it, the DP problem that seemed impossible to optimize using data structures, had a very simple greedy solution, if you just thought about it from a different perspective. But sometimes, we get too focused on one thing that we fail to see the bigger picture. It helps to take a step back and think of things from a different angle.
This problem appeared in a recent LeetCode contest, by the name 3282. Reach End of Array With Max Score. The problem is labelled as medium, and of course, once you see the solution, it’s very easy to prove.
But is it really a medium level problem though? Does the lines of code determine the difficulty? According to me, this is at least an LC hard problem. What are your thoughts? Let me know in the comment section of this Codeforces blog.